
![]() ฝันไว้ว่าอยากทำระบบที่สามารถคุยตอบโต้กับคอมพิวเตอร์แบบจาร์วิสใน IRON MAN มานานแล้วครับ แต่ก็ได้แค่ฝันเพราะผมเองก็ไม่มีความสามารถที่จะทำได้ขนาดนั้น แต่เราก็ยังพอจะสร้างจาร์วิสแบบโง่ๆ ด้วยงบประมาณไม่มากขึ้นมาจาก Raspberry Pi ได้เช่นกันครับ โดยสิ่งที่เราต้องมีก็คือ Raspberry Pi + ลำโพง + ไมโครโฟน โดยเราจะใช้โปรแกรมที่ชื่อว่า Snowboy Hotword Detection ข้อดีของเจ้าตัวนี้ก็คือว่ามันฟรีสำหรับ hacker อย่างเรา และสามารถสร้างโมเดลของคำที่ต้องการได้ไม่ยาก ซึ่งเจ้า Snowboy เนี้ยก็มี library ให้ใช้ได้อยู่หลายภาษาตามแต่ถนัดเลยครับ แต่ภาษาที่เราจะใช้เขียนวันนี้จะใช้เป็น Node.js
ฝันไว้ว่าอยากทำระบบที่สามารถคุยตอบโต้กับคอมพิวเตอร์แบบจาร์วิสใน IRON MAN มานานแล้วครับ แต่ก็ได้แค่ฝันเพราะผมเองก็ไม่มีความสามารถที่จะทำได้ขนาดนั้น แต่เราก็ยังพอจะสร้างจาร์วิสแบบโง่ๆ ด้วยงบประมาณไม่มากขึ้นมาจาก Raspberry Pi ได้เช่นกันครับ โดยสิ่งที่เราต้องมีก็คือ Raspberry Pi + ลำโพง + ไมโครโฟน โดยเราจะใช้โปรแกรมที่ชื่อว่า Snowboy Hotword Detection ข้อดีของเจ้าตัวนี้ก็คือว่ามันฟรีสำหรับ hacker อย่างเรา และสามารถสร้างโมเดลของคำที่ต้องการได้ไม่ยาก ซึ่งเจ้า Snowboy เนี้ยก็มี library ให้ใช้ได้อยู่หลายภาษาตามแต่ถนัดเลยครับ แต่ภาษาที่เราจะใช้เขียนวันนี้จะใช้เป็น Node.js
อย่างแรกเลย เตรียมอุปกรณ์ต่างๆ ให้เรียบร้อย Raspberry Pi + ลำโพง + ไมโครโฟน

ก่อนลงมือทำอย่างอื่นให้ทำการอัพเดทระบบก่อนครับ
1 2 | sudo apt-get update sudo apt-get upgrade |
จากนั้นทำการติดตั้ง Node.js และติดตั้ง developer tools ต่างๆ ให้พร้อมใช้งาน
1 2 3 4 | curl -sL https://deb.nodesource.com/setup_6.x | sudo -E bash - sudo apt-get install nodejs sudo apt-get install sox libmagic-dev libatlas-base-dev sudo apt-get install build-essential |
กำหนด NODE_PATH เพื่อให้เรียกใช้งานโมดูลของ Node.js ที่ติดตั้งแบบ global ได้ เพราะเดียวเราจะติดตั้งโมดูทั้งหมดเป็นแบบ global
1 | export NODE_PATH=/usr/lib/node_modules |
เมื่อติดตั้งเสร็จแล้ว ลองเช็คดูก่อนว่าสามารถเรียกใช้คำสั่ง node และ npm ได้ปกติแล้ว ง่ายๆ ก็ลองสั่งให้แสดง version ขึ้นมาดูก่อนเลย
1 2 | node -v npm -v |
ขั้นตอนถัดไปให้ทำการคอนฟิกและทดสอบลำโพงกับไมโครโฟน แต่ก่อนอื่นเราต้องทราบก่อนว่าทั้งลำโพงและไมโครโฟนมันต่ออยู่ที่ card id และ device id อะไร เพราะเดียวเราต้องใช้ทั้ง card id และ device id ตัวนี้ในการคอนฟิกในขั้นตอนถัดไป
ตรวจสอบหมายเลข card id และ device id ของลำโพง
1 | aplay -l |
จากรูปจะเห็นว่ามี card อยู่หลายใบ ให้สั่งเกตุหมายเลข card id และ device id ที่ผมไฮไลท์เอาไว้ด้วยนะครับ ให้เลือกใช้ card id และ device id อันที่ลำโพงเราต่ออยู่ (ข้างหลังมันมีชื่อรุ่นบอก น่าจะพอเดาได้อยู่)

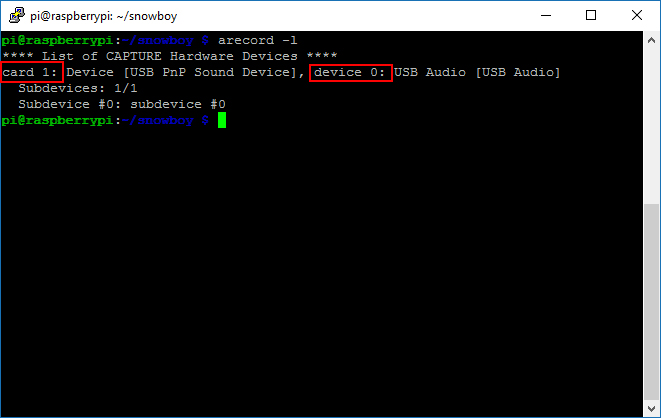
ตรวจสอบหมายเลข card id และ device id ของไมโครโฟน
1 | arecord -l |
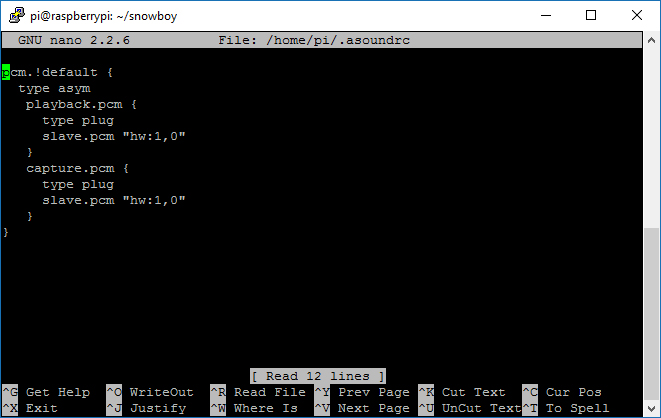
ทำการสร้างไฟล์ ~/.asoundrc เพื่อกำหนดค่า default ของลำโพงและไมโครโฟนให้ระบบ
1 | nano ~/.asoundrc |
โดยให้พิมพ์คำสั่งตามนี้ลงไป จะเห็นว่าในช่องของ playback.pcm ซึ่งก็คือลำโพงของเรา ให้เราใส่ hw:1,0 ซึ่งเป็นหมายเลข card id , device id ในที่นี้ก็คือ card 1, device 0 และสำหรับ capture.pcm ซึ่งเป็นไมโครโฟน ให้เราใส่เป็น hw:1,0 ซึ่งก็คือไมโครโฟนจาก card 1, device 0 (ถ้าหาก card id และ device id ของท่านแตกต่างจากนี้ก็ให้ใส่ให้ตรงกับของตัวเองด้วยนะครับ)
1 2 3 4 5 6 7 8 9 10 11 | pcm.!default { type asym playback.pcm { type plug slave.pcm "hw:1,0" } capture.pcm { type plug slave.pcm "hw:1,0" } } |
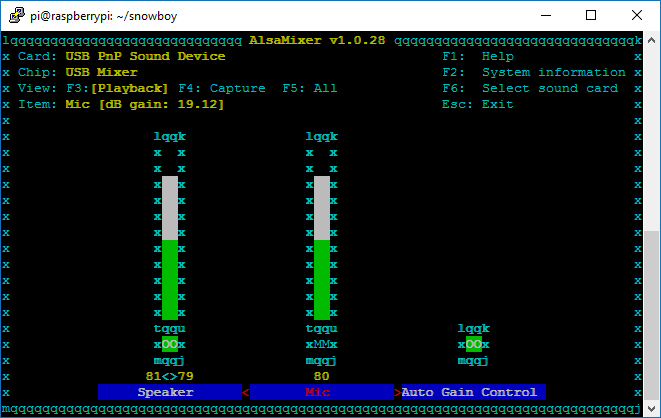
เราสามารถปรับความดังของลำโพงและไมโครโฟนได้โดยใช้คำสั่ง alsamixer (ถ้าท่านใช้ตัวแปลง USB To Sound Adapter เพื่อทำการแปลงสาย USB เป็น 3.5mm เพื่อใช้เสียบลำโพงกับไมโครโฟนแบบผม ก็ให้กด F6 เพื่อเลือก device ก่อนนะครับ)
1 | alsamixer |
ทำการทดสอบการบันทึกเสียงจากไมโครโฟน ให้สั่ง rec test.wav และพูดใส่ไมโครโฟนและถ้าต้องการหยุดให้กด CTRL+C
1 | rec test.wav |
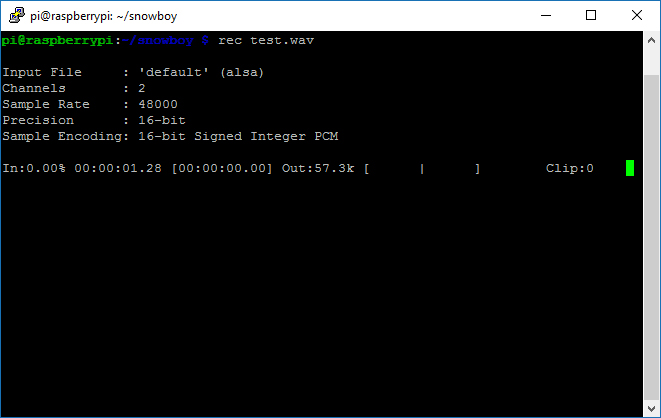
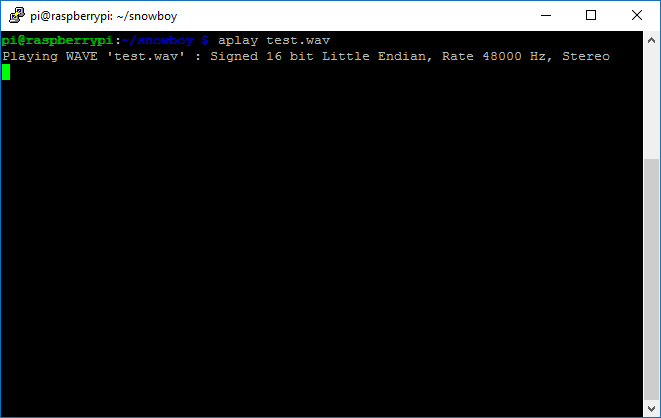
ลองสั่ง play เสียงที่เราบันทึกไว้เมื่อสักครู่นี้
1 | aplay test.wav |
ขั้นตอนถัดไปให้ทำการติดตั้ง snowboy และโมดูลต่างๆ ที่ต้องใช้งาน โดยเราจะติดตั้งทั้งหมดเป็นแบบ global ไปเลยนะครับ
1 2 3 | sudo npm install -S -g snowboy sudo npm install -S -g node-record-lpcm16 sudo npm install -S -g play-sound |
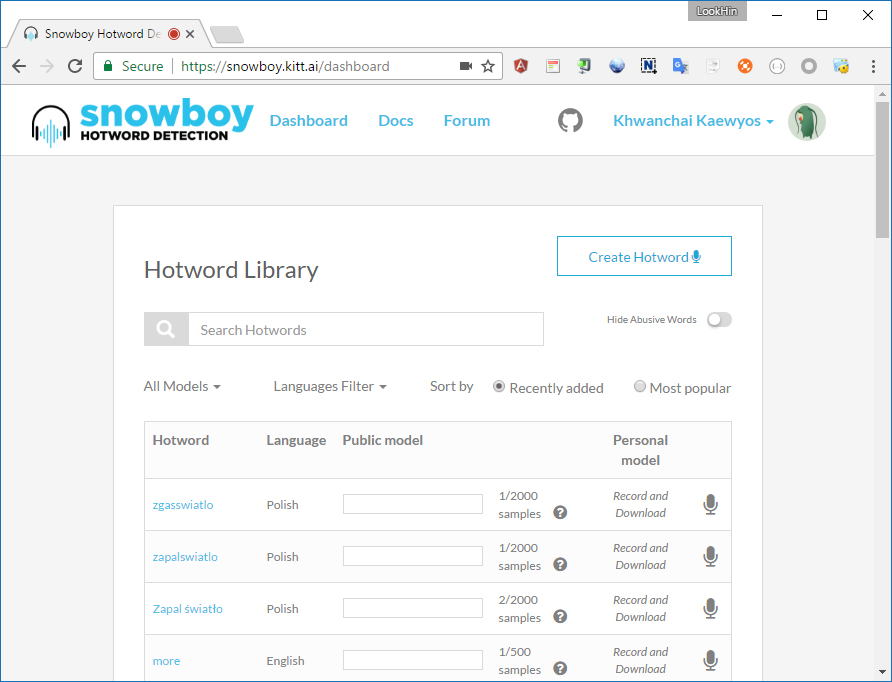
ต่อไปเป็นการสร้างโมเดลเสียงของคำที่ต้องการ โดยให้เข้าไปที่ https://snowboy.kitt.ai/dashboard จะเห็นปุ่ม Create Hotword คลิกเลยครับ
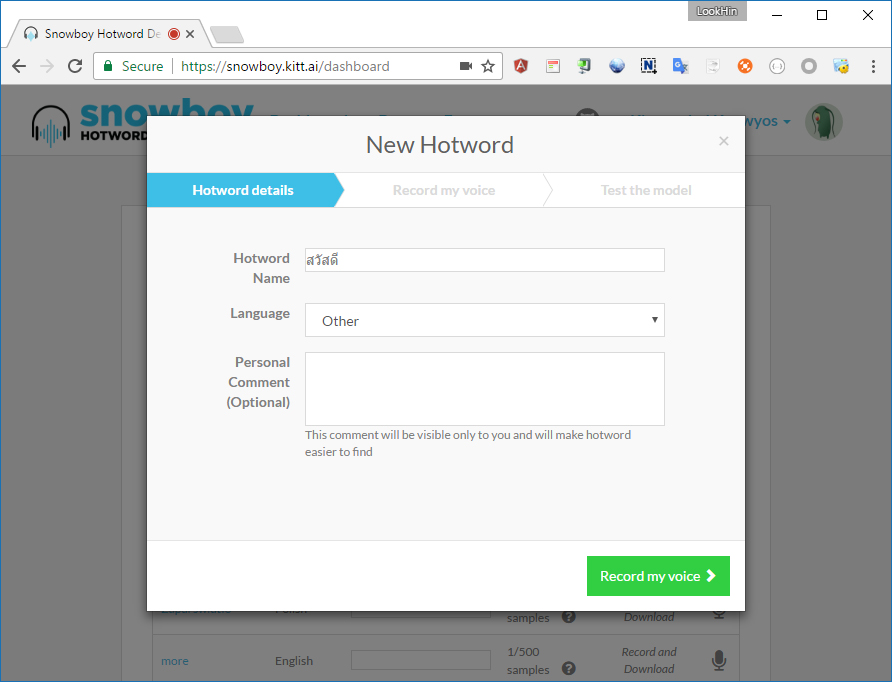
ทำการตั้งชื่อและเลือกภาษาให้เรียบร้อย แต่ระบบยังไม่มีภาษาไทยให้เลือกนะ ให้เราเลือกเป็น Other ไปก่อนนะ ผมลองแล้วก็ได้เหมือนกัน
ขั้นตอนถัดไปเป็นการบันทึกเสียง ให้เราบันทึกเสียงของคำที่เราต้องการลงไป 3 ครั้ง
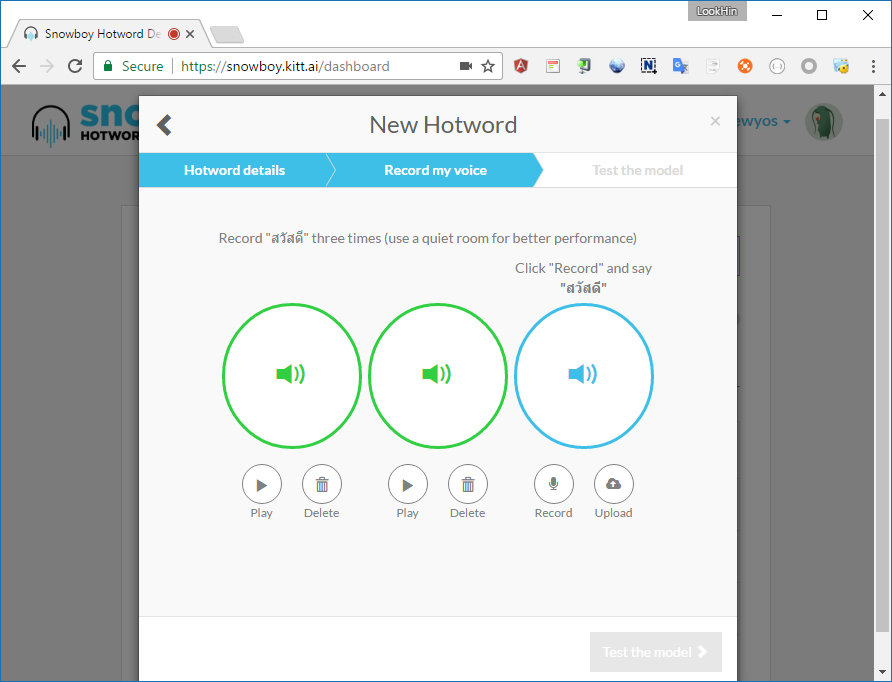
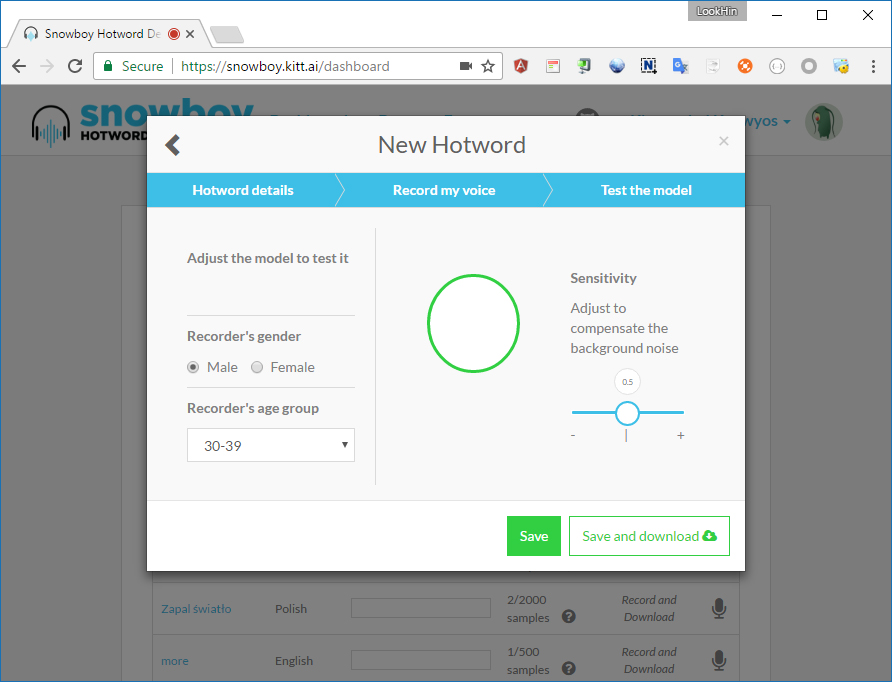
ขั้นตอนสุดท้ายเป็นการทดสอบและดาวน์โหลดโมเดลเสียงของเรา โดยเราจะได้มาเป็นไฟล์ .pmdl ดาวน์โหลดมาเก็บไว้ให้เรียบร้อยครับ
หลังจากติดตั้งโปรแกรมและสร้างไฟล์โมเดลของเสียงเรียบร้อยแล้วให้ทำการดาวน์โหลดโค้ดที่ผมเตรียมไว้ไปทดสอบรันได้เลยครับ Download Showboy Example โดยในโค้ดตัวอย่างจะมีไฟล์ snowboy.js ให้ทำการเปิดโค้ดขึ้นมาดูก่อนเลยครับ จะเห็นว่าในตัวอย่างผมมีโมเดลของคำสั่งเสียงอยู่ 2 ตัวคือ thai-hello.pmdl และ thai-what-is-your-name.pmdl ให้เอาโมเดลเสียงของตัวเองมาแทน 2 ไฟล์นี้นะครับ
snowboy.js
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | const record = require('node-record-lpcm16'); const Detector = require('snowboy').Detector; const Models = require('snowboy').Models; const player = require('play-sound')(opts = {}) const models = new Models(); models.add({ file: 'thai-hello.pmdl', sensitivity: '0.5', hotwords: 'Hello' }); models.add({ file: 'thai-what-is-your-name.pmdl', sensitivity: '0.5', hotwords: 'What\'s your name' }); const detector = new Detector({ resource: "common.res", models: models, audioGain: 2.0 }); detector.on('silence', function() { //console.log('silence'); }); detector.on('sound', function() { //console.log('sound'); }); detector.on('error', function() { //console.log('error'); }); detector.on('hotword', function(index, hotword) { console.log('Index='+index+', Hotword='+hotword); if(index == 1){ player.play('sound-hello.wav', function(err){ //console.log('play sound'); }); }else if(index == 2){ player.play('sound-my-name.wav', function(err){ //console.log('play sound'); }); } }); const mic = record.start({ threshold: 0, verbose: false }); mic.pipe(detector); |
เรียบร้อยแล้วครับ ให้สั่งรัน node snowboy.js และพูดคำสั่งที่เราตั้งไว้ได้เลยครับ
1 | node snowboy.js |
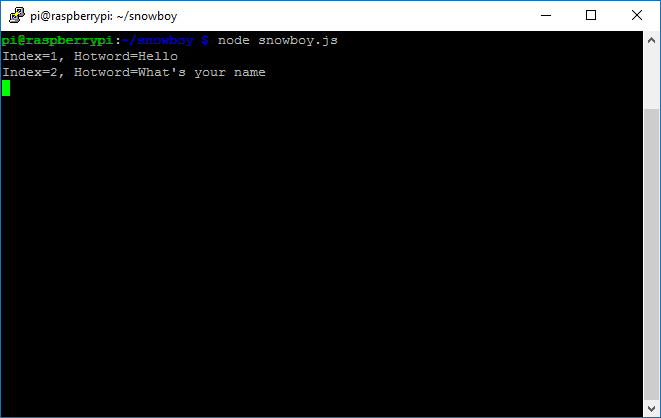
หากติดขัดปัญหาใดค้นหาข้อมูลเพิ่มเติมจาก Google และอ่านรายละเอียดได้จากแหล่งอ้างอิงครับ
หมายเหตุ : ในไฟล์ตัวอย่างระบบจะบอกว่าตัวเองชื่ออาร์เรย์ พอดีเพิ่งมาคิดชื่อบทความได้ทีหลังว่าจะใช้จาร์วิส แต่ไม่อยากกลับไปแก้เลยทิ้งไว้อย่างนั้น
อ้างอิง :
https://snowboy.kitt.ai/
http://docs.kitt.ai/snowboy/
https://github.com/kitt-ai/snowboy
https://www.npmjs.com/package/snowboy

